Byte-Sized Brain
Post-training quantization, measured honestly across four model families.
How much smaller and faster does quantization really make a model, and what does it cost you in accuracy? Byte-Sized Brain trains four models, quantizes each with the technique that fits it, and measures size, accuracy, latency, and memory the same way for all of them, on x86 and ARM64.
Get the code on GitHub Read the methodology
The headline
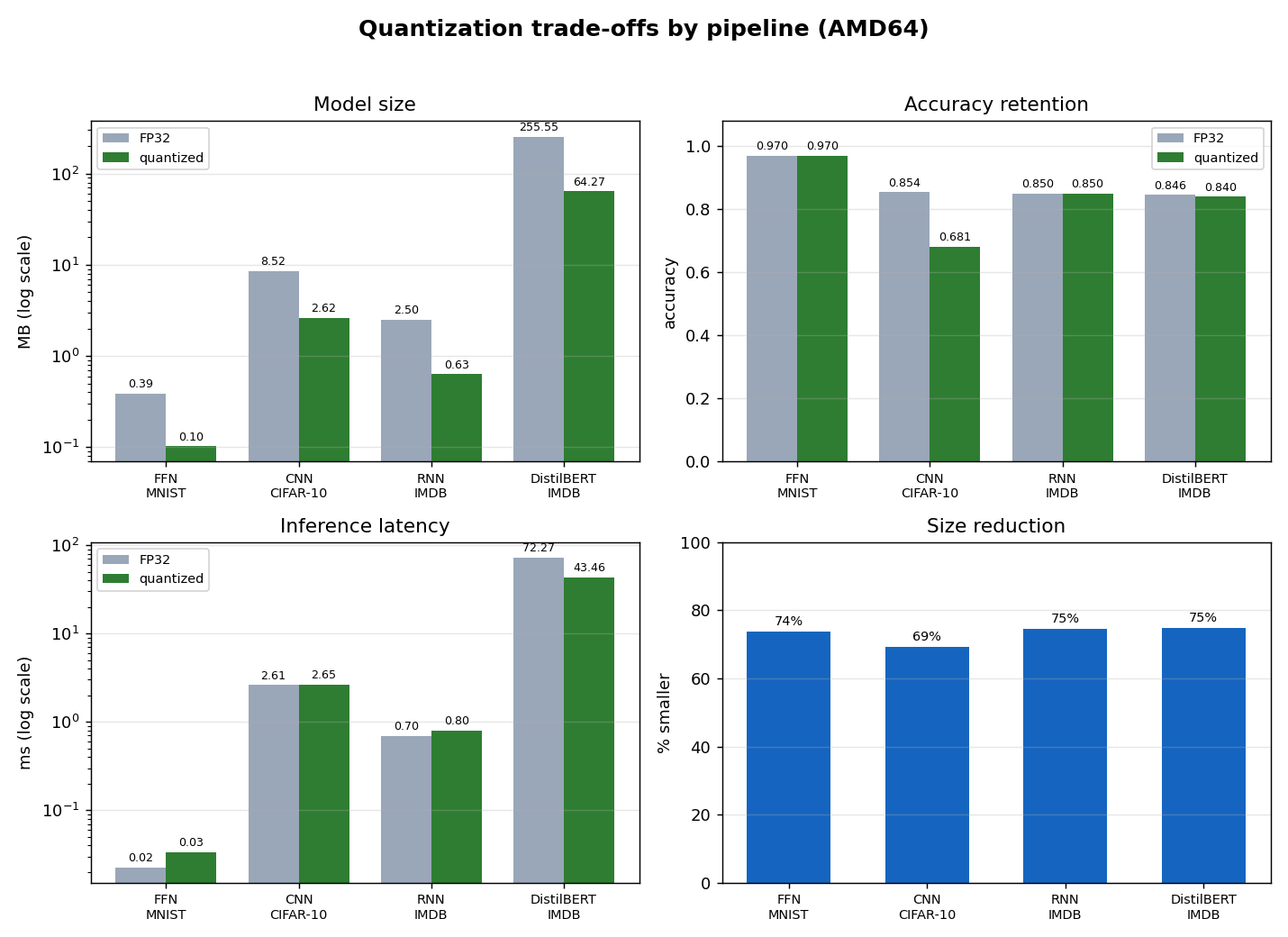
Every model came out about 70 percent smaller. For three of the four that was basically free, with accuracy holding to within about 2 percent. The MobileNetV2 CNN is the honest exception, dropping roughly 17 points, because depthwise-convolution networks are hard to quantize under full-integer PTQ. On the transformer, INT8 was also about 1.7 times faster.
See the full results for the per-model breakdown, and the methodology for exactly how every number is measured.
What it covers
- Static INT8 with real calibration data, plus dynamic-range and dynamic INT8, chosen per model.
- TensorFlow and PyTorch, TFLite and ONNX Runtime, across vision, text, and sequence models.
- The same benchmark on x86 and ARM64, containerized and reproducible.
- Config files, fixed seeds, pinned dependencies, a real CLI, tests, and CI.