▶ Live demo · GitHub repo · Project report (PDF) · Slides
What this is
Most “GraphRAG beats RAG” demos are confounded — the graph pipeline quietly also gets a reranker, a different corpus, or even leaks the answer into the prompt. This project runs a 4-arm ablation on PubMedQA where every layer (corpus, chunking, embedder, reranker, prompt, LLM, top-k, seed) is held constant, so the accuracy change between adjacent arms is attributable to exactly one component — verified with a paired McNemar test.

Results (n = 200, seed 42)
| Arm | Accuracy | Macro F1 | Adds |
|---|---|---|---|
plain |
30.0% | 29.7% | baseline chunk RAG |
plain_rr |
37.0% | 35.2% | + cross-encoder reranker |
graph |
59.5% | 50.5% | + parent-paper expansion |
graph_concepts |
57.5% | 50.0% | + MeSH concept hop |
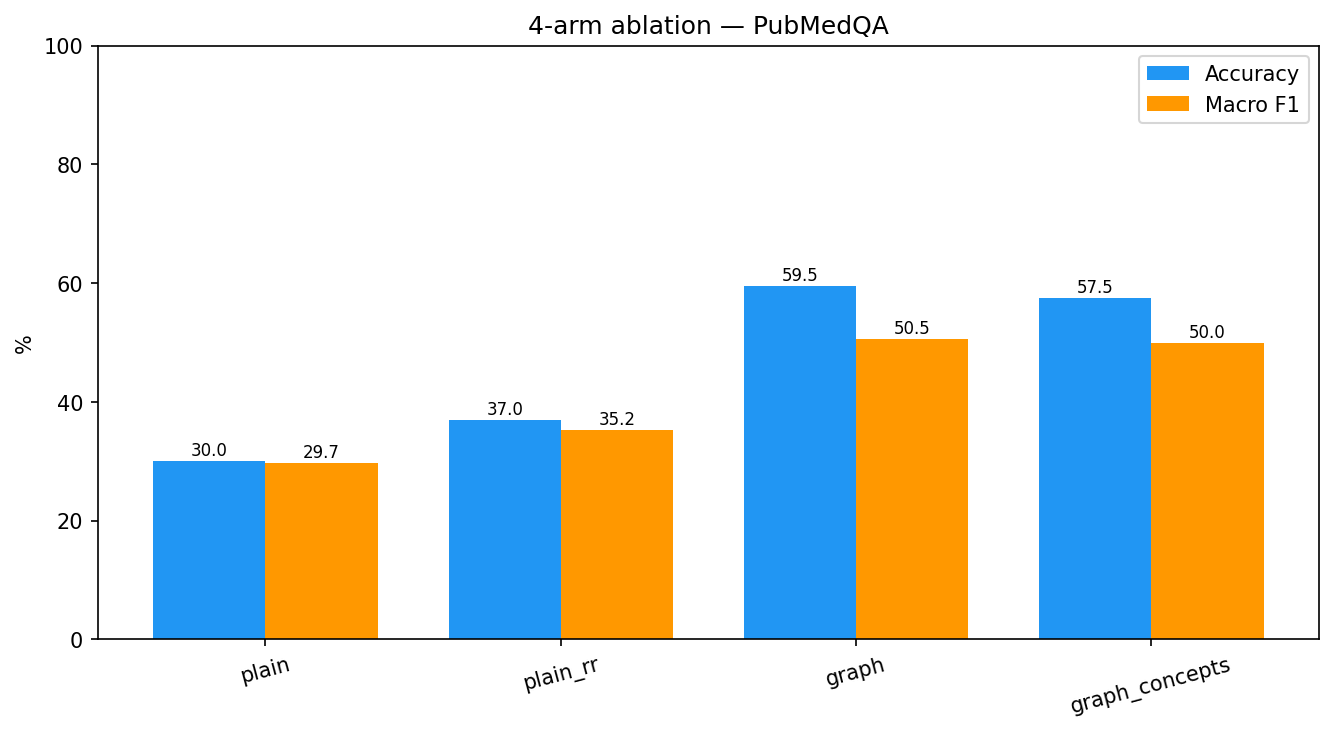
The honest finding: the graph’s decisive, statistically significant win comes
from parent-document expansion (plain_rr → graph: +22.5 pp, McNemar
p < 0.0001). The reranker helps but isn’t significant (+7 pp, p = 0.08), and
MeSH concept-hop expansion does not help on this single-abstract dataset
(−2 pp, p = 0.69) while costing ~5× the latency. The graph helps by deepening
context, not by broadening it.
Explore
- Live results dashboard — interactive bars, significance tests, per-class breakdown
- Source code & README — package, scripts, tests, CI
- Project report (PDF) and slides